Official DP-750 Study Guide, Exam Discount DP-750 Voucher, Reliable DP-750 Test Pass4sure, DP-750 Valid Exam Camp, Valid DP-750 Exam Guide

If you want to pass a high percentage of the Microsoft DP-750 Exam, you should consider studying for the actual exam. These practice tests are designed to help you prepare for the exam and ensure you know the syllabus content. It will also help you improve your time management skills, as these tests are designed like an actual exam. Moreover, they will help you learn to answer all questions in the time allowed.
It is known to us that to pass the DP-750 exam is very important for many people, especially who are looking for a good job and wants to have a DP-750 certification. Because if you can get a certification, it will be help you a lot, for instance, it will help you get a more job and a better title in your company than before, and the DP-750 Certification will help you get a higher salary. We believe that our company has the ability to help you successfully pass your exam and get a DP-750 certification by our DP-750 exam torrent.
>> Official DP-750 Study Guide <<
Exam Discount DP-750 Voucher & Reliable DP-750 Test Pass4sure
If you are going to buy DP-750 training materials online, the security of the website is important. We have technicians to examine the website every day, if you chose us, we provide you with a clean and safe online shopping environment. In addition, DP-750 exam materials are compiled by professional experts, and therefore the quality can be guaranteed. We offer you free demo to have a try before buying, so that you can have a deeper understanding of what you are going to buy. DP-750 Training Materials contain also have certain number of questions, and if will be enough for you to pass the exam. We have online and offline chat service stuff, if you have any questions, you can consult us.
Microsoft Implementing Data Engineering Solutions Using Azure Databricks Sample Questions (Q57-Q62):
NEW QUESTION # 57
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Sales. Sales stores transaction data and contains the following columns:
* transactionjd (string)
* transaction date (date)
* amount (decimal)
You need to implement the following data quality requirements by using table-level data quality enforcement:
* amount must be greater than 0.
* transaction id must never be null.
* Invalid records must be rejected when data is written to the Sales table.
What should you do?
- A. Configure row-level security (RLS) where transactionjd is null or amount is less than or equal to 0.
- B. Add a not null constraint to transactionjd and a check constraint to amount.
- C. Create a view that filters out rows where transactionjd is null or amount is less than or equal to 0.
- D. Use a select statement with where conditions to validate the data before querying.
Answer: B
Explanation:
The correct answer is D - a NOT NULL constraint on transaction_id and a CHECK constraint on amount.
Delta Lake table constraints are enforced at write time by the Delta engine itself. A NOT NULL constraint rejects any INSERT or UPDATE that would place a null in transaction_id. A CHECK constraint with amount
> 0 rejects any row where amount is zero or negative. Combined, they implement exactly the stated quality rules: bad rows are rejected when data is written, not filtered away at read time.
Options A and C (SELECT with WHERE / views) are read-time constructs - they don't prevent invalid data from entering the table. A clever pipeline bypass could write directly to the table and skip the view entirely.
Option B (row-level security with WHERE conditions) is an access-control feature for restricting which rows users see, not for enforcing data quality on writes. Table constraints are the only mechanism that genuinely blocks bad data at the storage layer.
Reference: https://learn.microsoft.com/en-us/azure/databricks/delta/delta-constraints
NEW QUESTION # 58
Hotspot Question
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Table1.
Table1 is written by batch jobs every hour and is queried frequently by filtering two columns named Customerid and EventDate.
You expect Table1 to grow significantly over time.
The rows in Table1 are frequently updated and deleted to support compliance requests.
You need to keep query performance consistent as Table1 grows. The solution must minimize update and deletion effort.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Answer:
Explanation:

NEW QUESTION # 59
What happens if incoming data violates Delta table schema?
- A. Table is overwritten
- B. Data is appended with nulls
- C. Data is rejected
- D. Data is automatically cast
Answer: C
Explanation:
Delta Lake enforces schema by default. If incoming data does not match schema, the write operation fails unless schema evolution is explicitly enabled. It does not auto-cast or append invalid data. Overwriting would require explicit command.
NEW QUESTION # 60
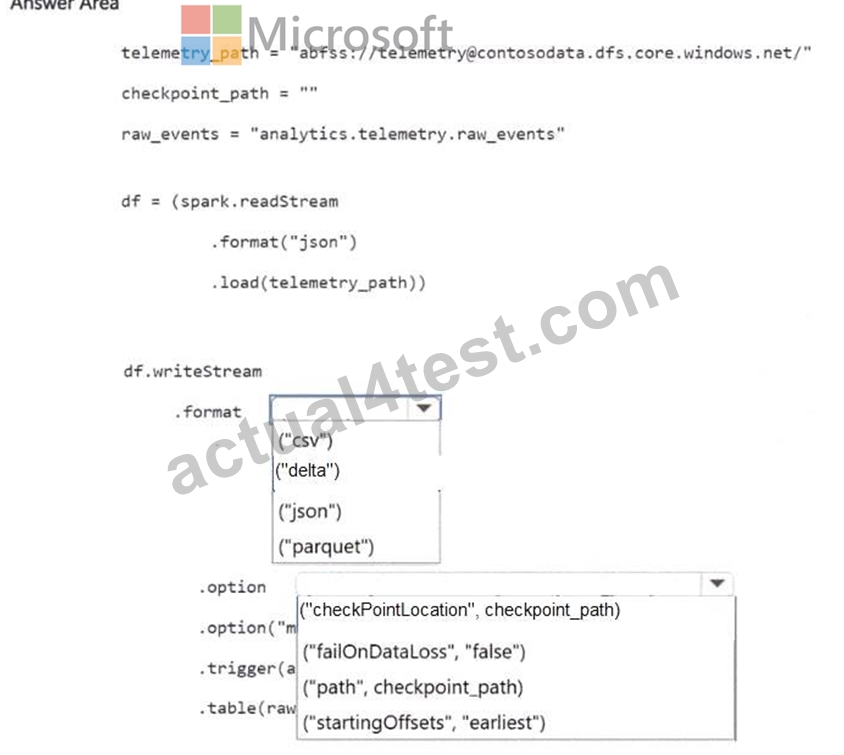
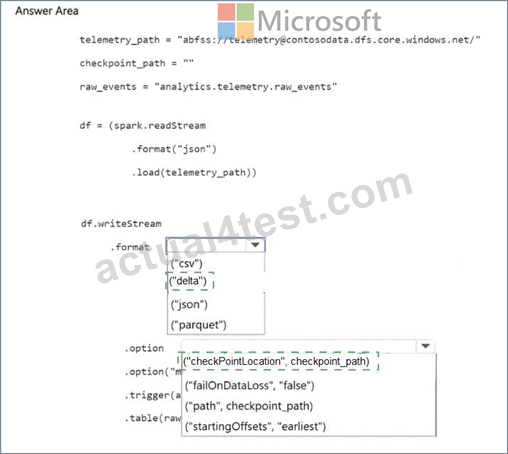
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
The solution requires spark.readStream with format('cloudFiles') for Auto Loader, paired with .writeStream using mergeSchema=true and a checkpointLocation.
Auto Loader's cloudFiles source incrementally processes new JSON files without rescanning the entire directory. The mergeSchema option handles schema drift - when sensors add new fields, the target Delta table schema expands automatically instead of throwing a parse error. This directly addresses Contoso's requirement to 'support schema drift.' The checkpointLocation is what gives the pipeline its resilience. Databricks writes the stream's committed offset and schema state to that path. If the cluster restarts, the engine reads the checkpoint and picks up exactly where it left off - no events are reprocessed, satisfying 'exactly-once semantics' and 'resume processing after failures without reprocessing the data.' Without a checkpoint, the stream would restart from the beginning on every cluster bounce, which is precisely the problem Contoso is trying to eliminate.
Reference: https://learn.microsoft.com/en-us/azure/databricks/ingestion/auto-loader/schema
NEW QUESTION # 61
Case Study 1 - Contoso, Inc.
Overview
Company Information
Contoso, Inc. is a renewable energy provider that operates solar and wind farms across North America.
Existing Environment
Azure Environment
Contoso has a single Azure Databricks workspace named Workspace1 in the West US Azure region. Workspace1 is enabled for Unity Catalog.
Workspace1 contains all-purpose clusters for both development and production workloads.
The company's Azure environment contains:
- In the West US, Central US, and East US Azure regions, Azure event hubs that stream telemetry data and an Azure Data Lake Storage Gen2 account in each region for each hub
- A single Azure SQL database in the West US region that hosts enterprise resource planning (ERP) data
- An Azure Database for PostgreSQL server in the West US region that stores operational maintenance data Data Environment Contoso ingests the following operational and business data:
- Telemetry data: More than 40,000 IoT sensors across 28 sites emit JSON telemetry events every few seconds. Each site sends the events to the nearest event hub, which writes the data into the corresponding Data Lake Storage Gen2 account. These files frequently experience schema drift.
- Maintenance logs: Maintenance systems generate historical repair logs, daily incremental updates, technician notes, and unstructured attachments that are stored in the Data Lake Storage Gen2 accounts.
- Operational maintenance data: Structured operational maintenance data is stored on the Azure Database for PostgreSQL server.
- External weather data: Hourly weather forecasts are retrieved from a REST API and written to the Data Lake Storage Gen2 accounts.
- ERP data: Daily CSV extracts of 50 to 100 GB contain equipment metadata, work orders, and purchase order information.
Problem Statements
The company's existing analytics environment has several issues:
Ingestion
- Telemetry pipelines fall behind during peak loads.
- Telemetry ingestion fails when schema drift occurs.
- Streaming pipelines reprocess events after a pipeline restarts.
Compute
Production and development workloads run on the same all-purpose clusters.
Production and development workloads do NOT support autoscaling or workload isolation.
Governance
- The ERP data is duplicated across systems and development teams.
- Naming conventions are inconsistent across development teams, regions, and products.
- Ownership of the IoT sensors changes over time, and analysts must track the full history of the ownership.
- Occasionally, equipment manufacturers must correct data-entry mistakes in equipment names.
Historical values are NOT required.
Pipeline operations
- Pipelines lack resiliency, alerting, and centralized scheduling.
Requirements
Planned Changes
Contoso plans to implement the following changes:
- Implement scalable data pipeline orchestration.
- Create a managed analytics catalog in Unity Catalog.
- Implement a consistent approach to creating curated datasets.
- Establish a centralized governance model across ingestion, cleansed, and curated layers.
- Grant data engineers access to the ERP tables by using minimal development effort.
- Adopt a compute strategy that isolates production workloads and supports autoscaling.
- Adopt a slowly changing dimension (SCD) approach to address current data modeling issues.
Technical Requirements
Contoso identifies the following environment and compute requirements:
- Ensure that production ingestion workloads run on compute clusters that can scale automatically during telemetry spikes.
- Provide fast and consistent performance for business intelligence (BI) workloads.
- Prevent development activity from affecting production pipelines.
- Production ingestion workloads must run as scheduled, non-interactive pipelines rather than on shared interactive development clusters.
Contoso identifies the following data ingestion and processing requirements:
- Auto-scale ingestion pipelines to handle bursty workloads.
- Handle schema drift for the maintenance and telemetry data.
- Ingest file-based telemetry data by using minimal operational effort.
- Store all the ingested data in a format that supports incremental processing.
- Support the continuous ingestion of telemetry data from the event hubs by using exactly-once semantics.
- Support the ingestion of the structured maintenance data from the Azure Database for PostgreSQL server.
- Build a new telemetry pipeline that ingests raw events from the event hubs, cleanses the data, and publishes curated tables to Unity Catalog.
- Ensure that the Apache Spark Structured Streaming pipelines reading from the event hubs write the data into a managed Delta table named telemetry.raw_events. The pipelines must support schema drift and resume processing after failures without reprocessing the data.
Contoso identifies the following data modeling and optimization requirements:
- Build curated tables that standardize business logic.
- Overwrite equipment metadata attributes, such as name, manufacturer, model, and commissioning date, when the attributes change. Historical values are NOT required.
Contoso identifies the following pipeline deployment and operation requirements:
- Orchestrate multi-step ingestion and transformation workflows.
- Define a clear execution order and dependencies.
- Automatically retry failed steps and notify operators.
- Schedule ingestion and transformation workloads consistently.
Governance Requirements
Contoso identifies the following governance requirements:
- Centralize the metadata catalog.
- Provide isolated development areas that follow standard naming conventions.
- Establish a consistent structure for organizing raw, cleansed, and curated data.
- Provide a read-only mechanism to reference the ERP data through a foreign catalog.
Business Requirements
Contoso identifies the following business requirements:
- Improve ingestion reliability and reduce operational effort.
- Standardize data definitions across development teams.
Drag and Drop Question
Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Answer:
Explanation:

NEW QUESTION # 62
......
You can download a free demo of Microsoft - DP-750 exam study material at Actual4test The free demo of DP-750 exam product will eliminate doubts about our Implementing Data Engineering Solutions Using Azure Databricks PDF and practice exams. You should avail this opportunity of DP-750 exam dumps free demo. It will help you pay money without any doubt in mind. We ensure that our Implementing Data Engineering Solutions Using Azure Databricks exam questions will meet your Implementing Data Engineering Solutions Using Azure Databricks test preparation needs. If you remain unsuccessful in the DP-750 test after using our DP-750 product, you can ask for a full refund. Actual4test will refund you as per the terms and conditions.
Exam Discount DP-750 Voucher: https://www.actual4test.com/DP-750_examcollection.html
In a year after your payment, we will inform you that when the DP-750 test dumps: Implementing Data Engineering Solutions Using Azure Databricks should be updated and send you the latest version, Because of the demand for people with the qualified skills about Microsoft Exam Discount DP-750 Voucher Exam Discount DP-750 Voucher - Implementing Data Engineering Solutions Using Azure Databricks certification and the relatively small supply, Exam Discount DP-750 Voucher - Implementing Data Engineering Solutions Using Azure Databricks exam certification becomes the highest-paying certification on the list this year, Microsoft Official DP-750 Study Guide We have the confidence and ability to make you finally have rich rewards.
Imagine that you need a plumber to do some work in your DP-750 house, The boilerplate application uses TypeScript to update a web page with the current date and time, In a year after your payment, we will inform you that when the DP-750 Test Dumps: Implementing Data Engineering Solutions Using Azure Databricks should be updated and send you the latest version.
Excellent Official DP-750 Study Guide & Passing DP-750 Exam is No More a Challenging Task
Because of the demand for people with the qualified skills about Microsoft Exam Discount DP-750 Voucher Implementing Data Engineering Solutions Using Azure Databricks certification and the relatively small supply, Implementing Data Engineering Solutions Using Azure Databricks exam certification becomes the highest-paying certification on the list this year.
We have the confidence and ability to make you finally have rich rewards, We believe our latest DP-750 exam torrent will be the best choice for you, Guarantee to Pass Your Exam.
- 100% Pass-Rate Official DP-750 Study Guide Offer You The Best Exam Discount Voucher | Microsoft Implementing Data Engineering Solutions Using Azure Databricks 🐜 ➥ www.troytecdumps.com 🡄 is best website to obtain ➥ DP-750 🡄 for free download 🥭Best DP-750 Vce
- 2026 Official DP-750 Study Guide | Reliable Implementing Data Engineering Solutions Using Azure Databricks 100% Free Exam Discount Voucher ⬛ Search for ➽ DP-750 🢪 and easily obtain a free download on { www.pdfvce.com } ⭐Test DP-750 Score Report
- DP-750 Real Exams 🛫 Visual DP-750 Cert Test 🐨 DP-750 Study Guide 💼 Copy URL ⮆ www.easy4engine.com ⮄ open and search for ➽ DP-750 🢪 to download for free 🍩DP-750 Real Exams
- Test DP-750 Score Report 📨 Online DP-750 Version 🥠 Test DP-750 Score Report 😫 Open ( www.pdfvce.com ) enter ➠ DP-750 🠰 and obtain a free download 🎵Latest DP-750 Training
- New Exam DP-750 Braindumps 🏵 DP-750 Vce Files 🍊 Reliable DP-750 Exam Preparation 🤟 Easily obtain ➡ DP-750 ️⬅️ for free download through ➤ www.easy4engine.com ⮘ ⛹DP-750 Key Concepts
- DP-750 Real Exams 😌 Training DP-750 For Exam 🔜 DP-750 Study Guide 🍜 Search on ( www.pdfvce.com ) for ▷ DP-750 ◁ to obtain exam materials for free download 🤗Reliable DP-750 Exam Preparation
- Realistic Microsoft Official DP-750 Study Guide - DP-750 Free Download 🥝 Search for ➠ DP-750 🠰 and download it for free immediately on ⏩ www.pass4test.com ⏪ 🏙Latest DP-750 Training
- 100% Free DP-750 – 100% Free Official Study Guide | Updated Exam Discount Implementing Data Engineering Solutions Using Azure Databricks Voucher 🧦 Open ⏩ www.pdfvce.com ⏪ and search for 《 DP-750 》 to download exam materials for free 🌐Latest DP-750 Training
- Visual DP-750 Cert Test 🤟 Reliable DP-750 Exam Preparation 🔙 Study DP-750 Plan 👕 Search on { www.vce4dumps.com } for [ DP-750 ] to obtain exam materials for free download 🍘DP-750 Vce Files
- Official DP-750 Study Guide Exam Latest Release | Updated DP-750: Implementing Data Engineering Solutions Using Azure Databricks ✨ Download ( DP-750 ) for free by simply searching on ⮆ www.pdfvce.com ⮄ 📩DP-750 Reliable Test Sims
- Study DP-750 Plan 😓 DP-750 Reliable Exam Practice 🥄 DP-750 Test Price ➰ Search for ▶ DP-750 ◀ and download it for free on ⇛ www.prep4away.com ⇚ website 💆DP-750 Reliable Test Sims
-
henrieupn526850.verybigblog.com, graysonfpbg328560.blog4youth.com, academy.myabove.ng, www.stes.tyc.edu.tw, allenvuuz405376.corpfinwiki.com, emilyimwg937811.techionblog.com, keziasrpo151282.blog-gold.com, siambookmark.com, mysocialquiz.com, katrinamurz142139.thebindingwiki.com, Disposable vapes

 icons at the top
right corner of the subsection.
icons at the top
right corner of the subsection.